Come segnalare a Google il plagio dei testi di un sito
Articolo di Fabio Di Matteo pubblicato il 16/07/2014
Esiste da pochi giorni uno strumento fondamentale per richiedere a Google l'assegnazione di diritti di proprietà di un testo, finalizzata ad evitare una penalizzazione in caso di contenuti duplicati. Il sistema è per ora disponibile esclusivamente in lingua inglese ma... tentare non nuoce.
Google ha di recente (2014) introdotto un nuovo sistema di calcolo del punteggio dei siti web. Tra le nuove metriche di classificazione dei siti è stata rivista (e potenziata) l'analisi dei contenuti duplicati, al fine di penalizzare i siti web che rubano contenuti (i cosiddetti "scrapers").
Con tale aggiornamento ai sistemi di calcolo Google ha di fatto escluso dai risultati di ricerca centinaia di migliaia di siti web, assegnando loro una penalizzazione che in alcuni casi ha comportato la perdita totale di traffico organico (il traffico proveniente dai motori di ricerca).
Considerando lo stravolgimento atteso, Google ha aperto una pagina web che può tornare utile ai proprietari dei siti web interessati a segnalare il plagio dei propri contenuti ad opera di terzi, informando così Google del reale proprietario dei testi in questione.
Si tratta di una mossa preventiva (per avvisare Google di un plagio in corso), ma anche di rettifica, utile per informare il Team qualità di Big G. di un errore nella valutazione dei nuovi algoritmi.
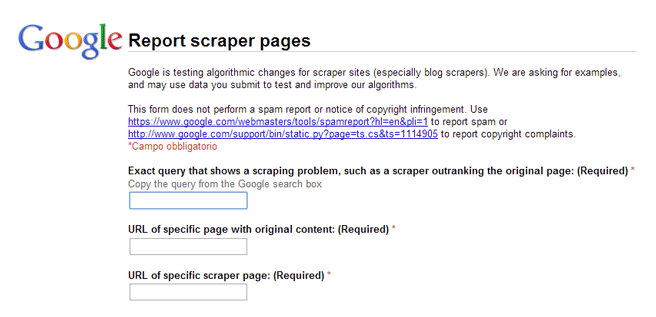
L'introduzione precedente il form recita "Google sta testando modifiche degli algoritmi per siti scrapers (specialmente blog scrapers). Chiediamo a voi esempi e potremmo utilizzare i dati che ci inviate per migliorare il nostro algoritmo".
Google ci sta chiaramente dicendo che tale form non dovrà essere utilizzato per richiedere un aiuto in caso di penalizzazione ma che, con le nostre segnalazioni, potremo aiutare il Team Qualità a migliorare gli algoritmi al punto di riuscire a penalizzare correttamente i veri scrapers.
Lo strumento, disponibile qui, è un form di contatto in cui inserire il testo clonato (così come lo cerchereste su Google), e i due URL in cui è presente (sito originale e sito clone), oltre ad eventuali note aggiuntive.
Perché mai dovremmo utilizzare un tale strumento?
Come mai Google non riesce da solo ad individuare il legittimo proprietario di un contenuto (ossia colui che l'ha pubblicato per primo)?
In realtà non è così semplice determinare quale sito, in prima istanza, ha pubblicato un testo presente su entrambi. Google infatti non scansiona i siti web quotidianamente e può accadere che, a seguito della pubblicazione del testo originale da parte del sito A, il sito clonante B duplichi i contenuti prima ancora che Google abbia registrato la data di prima pubblicazione di A.
In questo modo, Google è impossibilitato a stabilire la differenza temporale tra la prima referenza e la seconda.
Abbiamo osservato negli ultimi anni alcune penalizzazione da parte di Google per contenuti duplicati che hanno premiato il sito "ladro" e penalizzato il vero realizzatore dei contenuti.
Oltre al danno anche la beffa!
In molti casi, alcuni aggregatori (vedasi ad esempio Paperblog) continuano ancora oggi a prelevare conteuti dai blog della rete, fornendo un backlink DoFollow al sito originale (che normalmente indica a Google che si sta citando una fonte, quindi ammettendo che si sta duplicando il contenuto).
Purtroppo, stando all'attuale comportamento di Google, qualsiasi blog affiliato a tale aggregatore finisce per diventare il sito clone. Cercando infatti il titolo di un qualsiasi post aggregato, Paperblog viene portato in cima alle SERP (risultati di ricerca), mentre il proprietario originale dei contenuti, sbattuto in fondo alla lista, malgrado il link di citazione della fonte.
Questa situazione permane anche a diversi mesi dall'introduzione e rettifica dell'algoritmo Google Panda, che in altri casi aveva sanato questa malsana dinamica (con l'abbattimento di grande parte degli aggregatori della rete, compresi i famosi Wikio, Oknotizie e Liquida)
L'auspicio è che, grazie alle segnalazioni degli utenti, Google riveda le logiche che ancora tengono a galla siti scrapers, più o meno famosi, danneggiando i produttori di contenuti originali.